Resources
The majority of your text-based content and view templates in Bridgetown are processed as resources. A resource might be an informational page about you or your company, a blog post, an event, a podcast episode, a product.
Resource files contain front matter, metadata about the resource which can be used in other layouts and templates. For example, your about page (src/_pages/about.md) might be written like this:
---
layout: page
title: About Me
headshot: looking-good.jpg
---
Here's a page all about myself.
Here's what I look like:

In this example, the layout of the resource is specified as page, the title is “About Me” (which will be used by the layout and related templates), and a headshot filename is given which can then inform the final URL of the image in the body of the content.
You can save resources as files within your source tree, and you can also generate resources programatically via a builder plugin—perhaps based on data from a headless CMS or other third-party APIs.
Every resource you create is part of a collection. Bridgetown comes with two built-in collections, posts and pages, as well as a no-output data collection. You can easily create custom collections to group related content and facilitate easy pagination and archiving functionality.
Want to learn more about how to use resources effectively in your website structure and content strategy? Read on!
Table of Contents #
- Technical Architecture
- Accessing Resources in Templates
- Taxonomies
- Resource Relations
- Configuring Permalinks
- Slotted Content
- Ruby Front Matter and All-Ruby Templates
- Resource Extensions
- Upgrading Legacy Content to Use Resources
Technical Architecture #
The resource is a 1:1 mapping between a unit of content and a URL (remember the acronym Uniform Resource Locator?). A “unit of content” is typically a Markdown or HTML file along with YAML front matter saved somewhere in the src folder.
While certain resources don’t actually get written to URLs such as data files (and other resources and/or collections can be marked to avoid output), the concept is sound. Resources encapsulate the logic for how raw data is transformed into final content within the site rendering pipeline.
Resources come with a merry band of objects to help them along the way. These are called Origins, Models, Transformers, and Destinations. Here’s a diagram of how it all works.
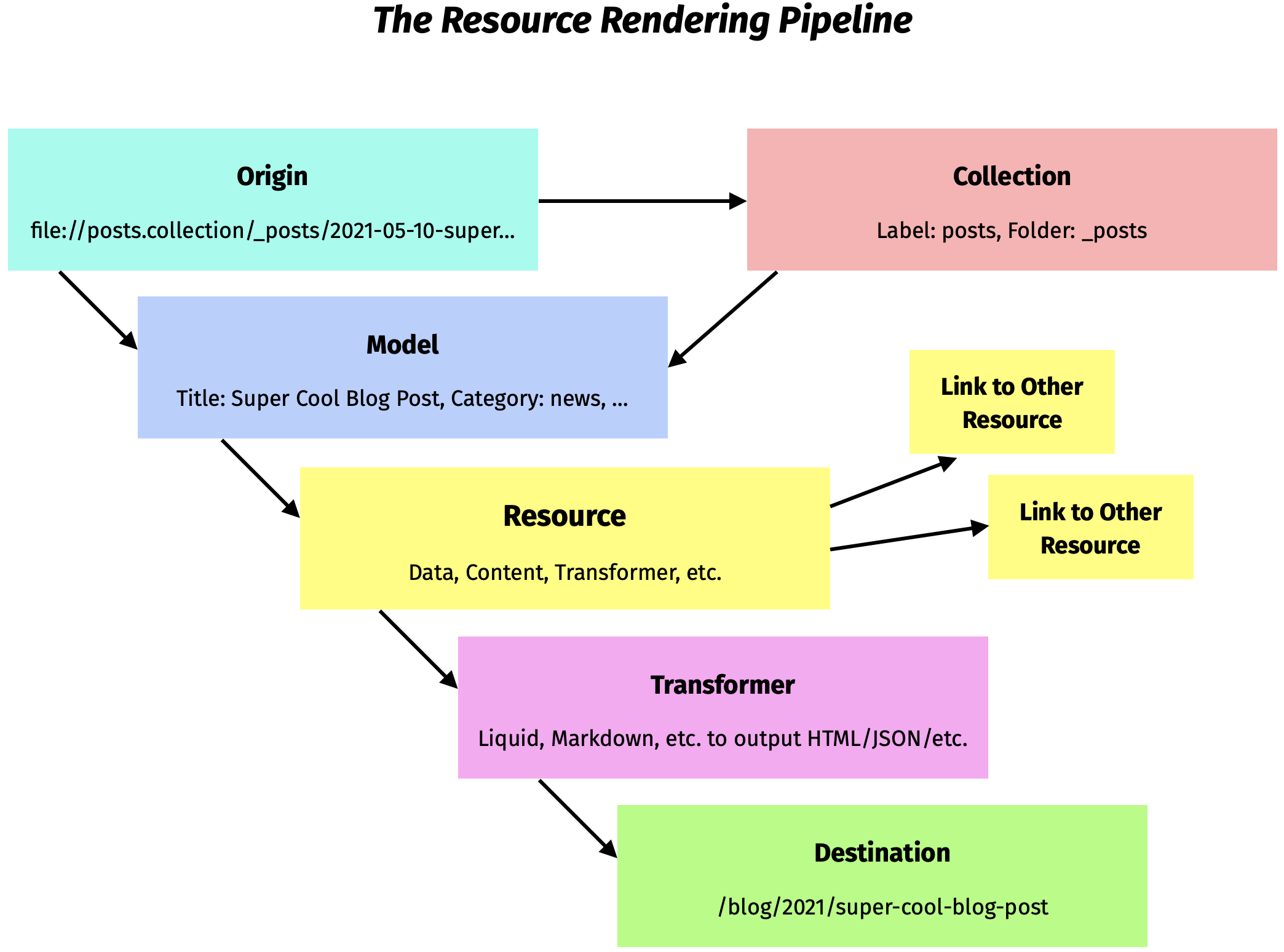
Let’s say you add a new blog post by saving src/_posts/2021-05-10-super-cool-blog-post.md. To make the transition from a Markdown file with Liquid or ERB template syntax to a final URL on your website, Bridgetown takes your data through several steps:
- It finds the appropriate origin class to load the post. The posts collection file reader uses a special origin ID to identify the file (in this case:
repo://posts.collection/_posts/2021-05-10-super-cool-blog-post.md). Other origin classes could handle different protocols to download content from third-party APIs or load in content directly from scripts. - Once the origin provides the post’s data it is used to create a model object. The model will be a
Bridgetown::Model::Baseobject by default, but you can create your own subclasses to alter and enhance data, or for use in a Ruby-based CMS environment. For example,class Post < Bridgetown::Model::Base; endwill get used automatically for thepostscollection (because Bridgetown will use the Rails inflector to mappoststoPost). You can save subclasses in yourpluginsfolder, or set up a dedicatedmodelsfolder to be eager-loaded by Zeitwerk. - The model then “emits” a resource object. The resource is provided a clone of the model data which it can then process for use within templates. Resources may also point to other resources through relations, and templates can access resources through various means (looping through collections, referencing resources by source paths, etc.)
- The resource is transformed by a pipeline to convert Markdown to HTML, render template code like Liquid or ERB, and any other conversions specified—as well as optionally place the resource output within a converted layout.
- Finally, a destination object is responsible for determining the resource’s “permalink” based on configured criteria or the presence of
permalinkfront matter. It will then write out to the output folder using a static file name matching the destination permalink.
Accessing Resources in Templates #
The simplest way to access resources in your templates is to use the collections variable, available in both Liquid and Ruby-based templates.
Title: {{ collections.genre.title }}
First URL: {{ collections.genre.resources[0].relative_url }}
Title: <%= collections.genre.metadata.title %>
First URL: <%= collections.genre.resources[0].relative_url %>
Loops and Pagination #
You can easily loop through collection resources by name, e.g., collections.posts.resources:
{% for post in collections.posts.resources %}
<article>
<a href="{{ post.relative_url }}"><h2>{{ post.data.title }}</h2></a>
<p>{{ post.data.description }}</p>
</article>
{% endfor %}
<% collections.posts.resources.each do |post| %>
<article>
<a href="<%= post.relative_url %>"><h2><%= post.data.title %></h2></a>
<p><%= post.data.description %></p>
</article>
<% end %>
Sometimes you’ll likely want to use a paginator:
{% for post in paginator.resources %}
<article>
<a href="{{ post.relative_url }}"><h2>{{ post.data.title }}</h2></a>
<p>{{ post.data.description }}</p>
</article>
{% endfor %}
<% paginator.resources.each do |post| %>
<article>
<a href="<%= post.relative_url %>"><h2><%= post.data.title %></h2></a>
<p><%= post.data.description %></p>
</article>
<% end %>
Read more about how the paginator works here. You can also refer to how collections work and how you can also create your own custom collections.
Taxonomies #
Bridgetown comes with two builtin taxonomies: category and tag.
Categories are usually used to structure resources in a way that affects their output URLs and easily match up with specialized archive pages. It’s a good way to “group” like-minded resources together.
Tags are considered more of a flat “folksonomy” that you can apply to resources which are purely useful for display, searching, or viewing related items.
You can use a singular front matter key “category / tag” or a plural “categories / tags”. If using the plural form but only providing a string, the categories/tags will be split via a space delimiter. Otherwise provide an array of values, like so:
categories:
- category 1
- another category 2
tags:
- blessed
- super awesome
In addition to the builtin taxonomies, you can define your own taxonomies. For example, if you were setting up a website all about music, you could create a “genre” taxonomy. Just set it up in the config:
# bridgetown.config.yml
taxonomies:
genre:
key: genres
title: "Musical Genre"
other_metadata: "can go here!"
Then use that front matter key in your resources:
genres:
- Jazz
- Big Band
Accessing taxonomies for resources in your templates is pretty straightforward.
Title: {{ site.taxonomy_types.genres.metadata.title }}
{% for term in resource.taxonomies.genres.terms %}
Term: {{ term.label }}
{% endfor %}
Title: <%= site.taxonomy_types.genres.metadata.title %>
<% resource.taxonomies.genres.terms.each do |term| %>
Term: <%= term.label %>
<% end %>
Resource Relations #
You can configure one-to-one, one-to-many, or many-to-many relations between resources in different collections. You can then add the necessary references via front matter or metadata from an API request and access those relations in your templates, plugins, and components.
For example, given a config of:
collections:
actors:
output: true
relations:
has_many: movies
movies:
output: true
relations:
belongs_to:
- actors
- studio
studios:
output: true
relations:
has_many: movies
The following data accessors would be available:
actor.relations.moviesmovie.relations.actorsmovie.relations.studiostudio.relations.movies
The belongs_to type relations are where you add the resource references in front matter—Bridgetown will use a resource’s slug to perform the search. belongs_to can support solo or multiple relations. For example:
# _movies/_1982/blade-runner.md
name: Blade Runner
description: A blade runner must pursue and terminate four replicants who stole a ship in space, and have returned to Earth to find their creator.
year: 1982
actors:
- harrison-ford # _actors/_h/harrison-ford.md
- rutger-howard # _actors/_r/rutger-howard.md
- sean-young # _actors/_s/sean-young.md
studio: warner-brothers # _studios/warner-brothers.md
Thus if you were building a layout for the movies collection, it might look something like this:
<h1><%= resource.data.name %> (<%= resource.data.year %>)</h1>
<h2><%= resource.data.description %></h2>
<p><strong>Starring:</strong></p>
<ul>
<% resource.relations.actors.each do |actor| %>
<li><%= link_to actor.name, actor %></li>
<% end %>
</ul>
<p>Released by <%= link_to resource.relations.studio.name, resource.relations.studio %></p>
The three types of relations you can configure are:
- belongs_to: a single string or an array of strings which are the slugs of the resources you want to reference
- has_one: a single resource you want to reference will define the slug of the current resource in its front matter
- has_many: multiple resources you want to reference will define the slug of the current resource in their front matter
The inflections between the various singular and plural relation names are handled by Bridgetown’s inflector automatically. If you need to customize the inflector with words it doesn’t specifically recognize, you can add additional rules in the config/initializers.rb file.
Configuring Permalinks #
Bridgetown uses permalink “templates” to determine the default permalink to use for resource destination URLs. You can override a resource permalink on a case-by-case basis by using the permalink front matter key. Otherwise, the permalink is determined as follows (unless you change the site config):
- For pages, the permalink matches the path of the file. So
src/_pages/i/am/a/page.mdwill output to “/i/am/a/page/”. - For posts, the permalink is derived from the categories, date, and slug (aka filename, but you can change that with a
slugfront matter key). - For all other collections, the permalink matches the path of the file along with a collection prefix. So
src/_movies/horror/alien.mdwill output to/movies/horror/alien/ - In addition, if multiple site locales are configured, any content not in the “default” locale will be prefixed by the locale key. So a page offering both English and French variations would be output to
/page-informationand/fr/page-information.
Refer to our permalinks documentation for further details on how to configure and custom generate permalinks.
Slotted Content #
When writing out your resource content and you’re using a Ruby-based template language such as ERB, you can provide extra content in the form of “slots” which won’t be included in the main body of the resource but will be available within layouts and partials. This is perfect for “out of band” content such as extra HTML for the <head> or info to display in a sidebar or footer. Check out the docs here.
Ruby Front Matter and All-Ruby Templates #
For advanced use cases where you wish to generate dynamic values for front matter variables, you can use Ruby Front Matter. Read the documentation here.
In addition, you can add all-Ruby page templates to your site besides just the typical Markdown/Liquid/ERB options. Yes, you’re reading that right: put .rb files directly in your src folder! As long as the final statement in your code returns a string or can be converted to a string via to_s, you’re golden. Ruby templates are evaluated in a Bridgetown::ERBView context (even though they aren’t actually ERB), so all the usual Ruby template helpers are available.
For example, if we were to convert the out-of-the-box about.md page to about.rb, it would look something like this:
###ruby
front_matter do
layout :page
title "About Us"
end
###
output = Array("This is the basic Bridgetown site template. You can find out more info about customizing your Bridgetown site, as well as basic Bridgetown usage documentation at [bridgetownrb.com](https://bridgetownrb.com/)")
output << ""
output << "You can find the source code for Bridgetown at GitHub:"
output << "[bridgetownrb](https://github.com/bridgetownrb) /"
output << "[bridgetown](https://github.com/bridgetownrb/bridgetown)"
markdownify output.join("\n")
Now obviously it’s silly to build up Markdown content in an array of strings in a Ruby code file…but imagine building or using third-party DSLs to generate sophisticated markup and advanced structural documents of all kinds. Arbre is but one example of a Ruby-first approach to creating templates.
# What if your .rb template looked like this?
Arbre::Context.new do
h1 "Hello World"
para "I'm a Ruby template. w00t"
end
Resource Extensions #
This API allows you or a third-party gem to augment resources with new methods (both via the Resource Liquid drop as well as the standard Ruby base class). In addition, the summary method is now available for resources. By default the first line of content is returned, but any resource extension can provide a new way to summarize resources by adding summary_extension_output. Check out the resource extension plugin page for more information.
Upgrading Legacy Content to Use Resources #
Prior to Bridgetown 1.0, a different content engine based on Jekyll was used which you may be familiar with if you have older Bridgetown sites in production or in progress.
- The most obvious differences are what you use in templates (Liquid or ERB). For example, instead of
site.postsin Liquid orsite.posts.docsin ERB, you’d usecollections.posts.resources(in both Liquid and ERB). (site.collection_name_heresyntax is no longer available.) Pages are just another collection now so you can iterate through them as well viacollections.pages.resources. - Front matter data is now accessed in Liquid through the
datavariable just like in ERB and skippingdatais deprecated. Use{{ post.data.description }}instead of just{{ post.description }}. - In addition, instead of referencing the current “page” through
page(akapage.data.title), you can useresourceinstead:resource.data.title. - Resources don’t have a
urlvariable. Your templates/plugins will need to reference eitherrelative_urlorabsolute_url. Also, the site’sbase_path(if configured) is built into both values, so you won’t need to prepend it manually. - Permalink formats have changed somewhat, so please refer to the latest permalink docs for how to use the new permalink styles and placeholders.
- Whereas the
idof a document is the relative destination URL, theidof a resource is its origin id. You can define an id in front matter separately however, which would be available asresource.data.id. - The paginator items are now accessed via
paginator.resourcesinstead ofpaginator.documents. - Instead of
pagination:\n enabled: truein your front matter for a paginated page, you’ll put the collection name instead. Also you can use the termpaginateinstead ofpagination. So to paginate through posts, just addpaginate:\n collection: poststo your front matter. - Prototype pages no longer assume the
postscollection by default. Make sure you add acollectionkey to theprototypefront matter. - Categories and tags are collated from all collections (even pages!), so if you used category/tag front matter manually before outside of posts, you may get a lot more site-wide category/tag data than expected.
- Since user-authored pages are no longer loaded as
Pageobjects and everything formerly loaded asDocumentwill now be aResource::Base, plugins will need to be adapted accordingly. ThePageclass has been renamed toGeneratedPageto indicate it is only used for specialized content generated by plugins. - With the legacy engine, any folder starting with an underscore within a collection would be skipped. With the resource engine, folders can start with underscores but they aren’t included in the final permalink. (Files starting with an underscore are always skipped however.)
- The
YYYY-MM-DD-slug.extfilename format will now work for any collection, not just posts. - The
docmethod in builder plugins has been replaced withadd_resource. See the Resource Builder API docs for further details. - The resource content engine doesn’t provide a related/similar result set using LSI classification. So there’s no direct replacement for the
related_postsfeature of the legacy engine. However, anyone can create a gem-based plugin using the new resource extension API which could restore this type of functionality.